Machine Learning
Machine learning is NOT magical! - Data exploration, model selection and evaluation
Overview
Teaching: 10 min Exercises: 0 minQuestions
What are good practices of building machine learning models?
How to objectively evaluate model performance?
What are some tools for model diagnosis?
Objectives
Understand the typical procedures of building machine learning models.
Understand the usage of training, validation and test sets.
Understand the basic concept of underfitting and overfitting (bias-variance trade-off).
Machine Learning is NOT Magical!
In an ideal world, machine learning, as a sub-category of artifical intelligence (AI), can automatically learn information from data. In reality, machine learning is still far from being that magical.
As we have seen in previous sections, there exist numerous machine learning algorithms. How should we choose the best algorithm for a specific problem? How do we evaluate model performance? In this section, we will talk about the typical procedure and good practices of building machine learning models.
Data Exploration: Always Try to Understand Your Data First!
Before building a machine learning model, always try to understand your data better. Various statistical and visualization tools can be used for exploratory data analysis (EDA), including:
-
Summary statistics (e.g., mean, variance, correlation between variables)
-
Histograms
-
Pairwise scatterplot matrix
A good understanding of the basic data behavior helps choose suitable models and is key to model diagnosis.
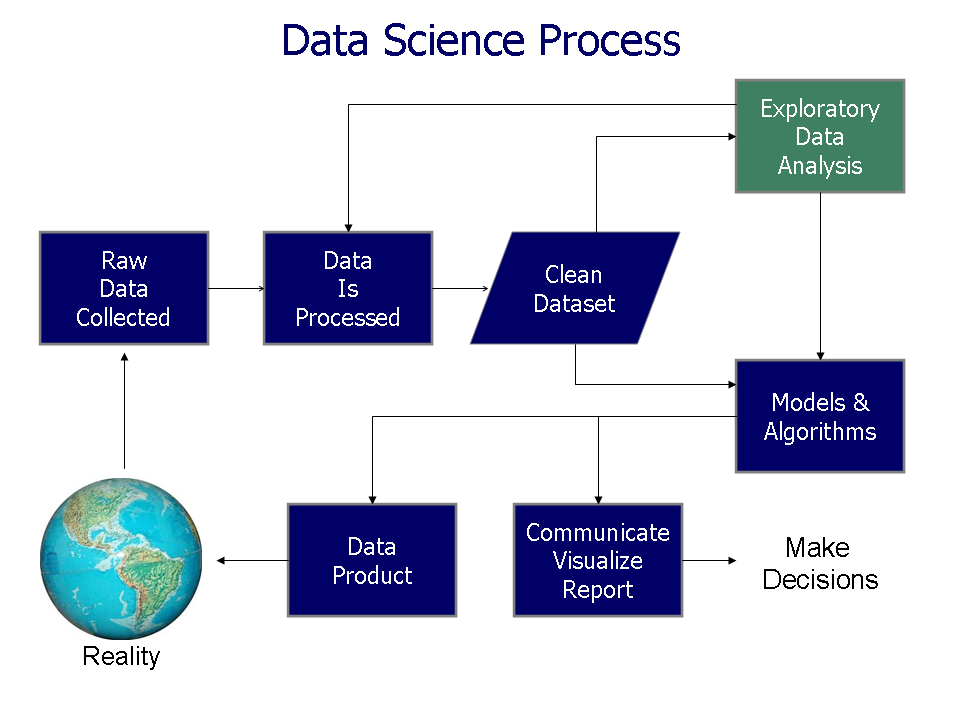
Figure: You need a solid understanding for your data before being effective with machine learning (image source: https://en.wikipedia.org/wiki/Exploratory_data_analysis).
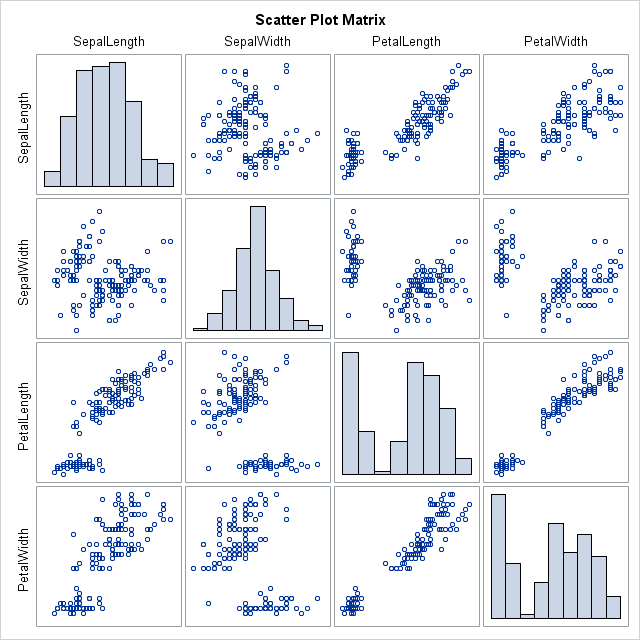
Figure: Example pairwise scatterplot matrix of multiple variables (image source: https://blogs.sas.com/content/iml/2011/08/26/visualizing-correlations-between-variables-in-sas.html).
Machine Learning Procedure: Training, Validation and Test Sets
Suppose we are facing a supervised learning problem, and have a set of observed input and outcome data. As a typical machine learning procedure, we divide the entire dataset into three subsets:
-
Training set: Models are fit on this dataset and model parameters are estimated
-
Validation set:
-
The fitted model is applied to predict the outcomes for input data in the validation set, and model performanceis evaluated (model performance can be quantified by metrics such as mean squared error (MSE) or hit rate).
-
A separate validation set provides an unbiased evaluation of a model fit on the training dataset
-
Performance on the validation set can be used to tune the model’s hyperparameters (e.g., the number of hidden units in a neural network) or select from multiple candidate models (e.g., linear regression versus polynomial regression).
-
-
Test set: A dataset used to provide an unbiased evaluation of a final model fit on the training dataset.
Rule of thumb for dividing the three subsets: the ratio of training : validation : test = 6:2:2 or 7:1.5:1.5 or 8:1:1
Underfitting and overfitting
The validation set provides the opportunity of diagnosing and improve model setup. Quite commonly, when we initially train a model, we might observe that:
-
The model performs poorly on both the training and validation sets
-
The model performance is much worse on the validation set than on the training set
To understand why these happen, we need to introduce the concept of model underfitting and overfitting. Typically:
-
An underfitting model:
-
Model is not complex enough to capture the underlying behavior of observed data
-
Model performs poorly on the training set, and similarly poorly on the validation set
-
-
An overfitting model:
-
Model fits the training set well, but is because of the limited number of training data points
-
Model performs much worse on the validation set than on the training set
-
In other words, if we have a complex enough model with insufficient data, we can always fit this data well, but the model performs poorly when generalized to an unseen dataset.
-
-
A good model - the sweet spot between underfitting and overfitting:
- It is important to examine and compare the model performance on the training and validation set in order to find the sweet spot!
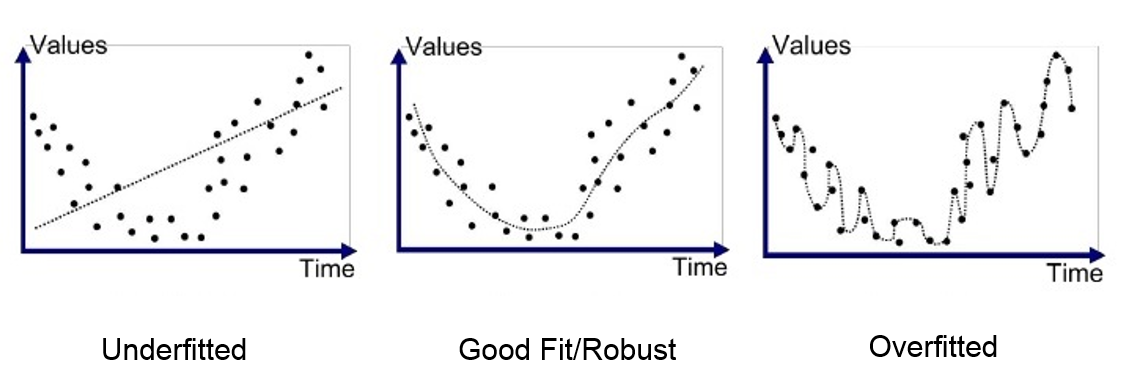
Figure: Illustration of underfitting and overfitting - regression example (image source: https://medium.com/greyatom/what-is-underfitting-and-overfitting-in-machine-learning-and-how-to-deal-with-it-6803a989c76)
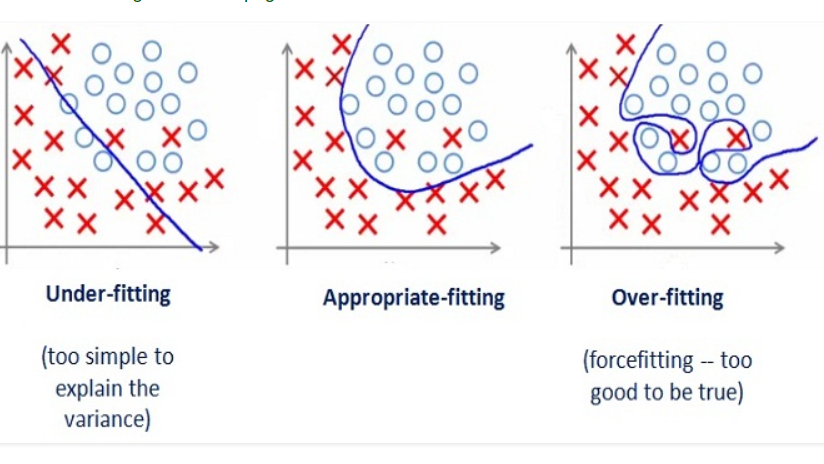
Figure: Illustration of underfitting and overfitting - classification example (image source: https://medium.com/greyatom/what-is-underfitting-and-overfitting-in-machine-learning-and-how-to-deal-with-it-6803a989c76)
Key Points
model evaluation, training set, validation set, test set, data exploration